- 1st Post Comparing Open Source BGP Stacks
- 3rd Post Comparing Open Source BGP stacks with internet routes
- 4th Post Bird on Bird, Episode 4 of BGP Perf testing
- 5th Post BGP Performance 5 – 1000 full internet neighbors
- 6th Post BGP Performance testing with filtering
- 7th Post Performance testing of Commercial BGP
After I published the post on measuring open source BGP stacks, I was embarrassed after I realized how haphazard the testing was. I was not very systematic about the way I tried different test parameters. So I hacked on bgperf, added some more reporting and created a new batch feature that iterates through parameters systematically, and automatically graphs the results. By request, I added RustyBGP and OpenBGPD. I’ve only added rudimentary support for these just to get started testing the number of prefixes and neighbors. RustyBGP isn’t yet a fully formed BGP stack; I don’t think it has much support for any kind of policy yet.
In these tests I stopped testing GoBGP, even though bgperf still supports it. As you can see from the previous post, it uses a lot more resources and is much slower. It makes the graphs much harder to interpret. I also only test the single table version of bird, because it’s the easier config and it’s faster.
Last time for FRR I (accidentally) used a dev version which took an excess amount of time establishing neighbors when there were > 30 neighbors. This time I’m using FRRouting 7.5.1 from dockerhub container and FRRouting 8.0 that bgperf compiled from github, neither of which have problems with neighbor times. I’m not going to show neighbor results here because for the most part they are uninteresting.
There are all kinds of different uses for BGP stacks. I try to cover a set of interesting scenarios to demonstrate how these perform.
The goal in all of this is to add some quantitative power to any decision making about different BGP stacks. It’s not the only aspect to consider, often it’s the least important.
Results
The first set of results we’ll look at are from my AMD 3950 32 core machine with 64 GB RAM.
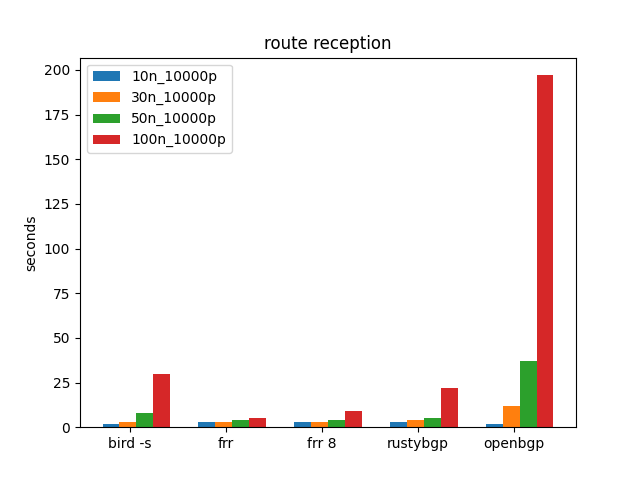
10K prefixes
We’ll start with 10K prefixes. It iterates through 10, 30, 50, and then 100 neighbors. It looks like 100 neighbors with each 10K prefixes is pretty taxing on many of these stacks.
Route reception is the time from the first route received until all routes are received.
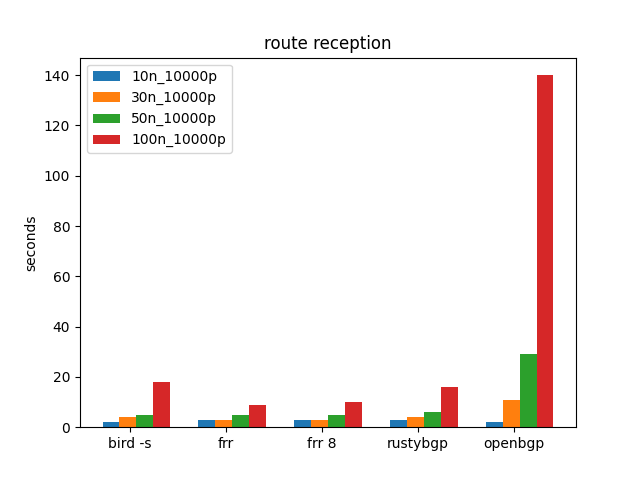
The first thing that jumps out is how much slower OpenBGPD is especially at 100, and even 50, neighbors. While harder to see, BIRD and RustyBGP at 100 neighbors are considerably slower than the two FRRoutings, 18s compared to 9-10s.
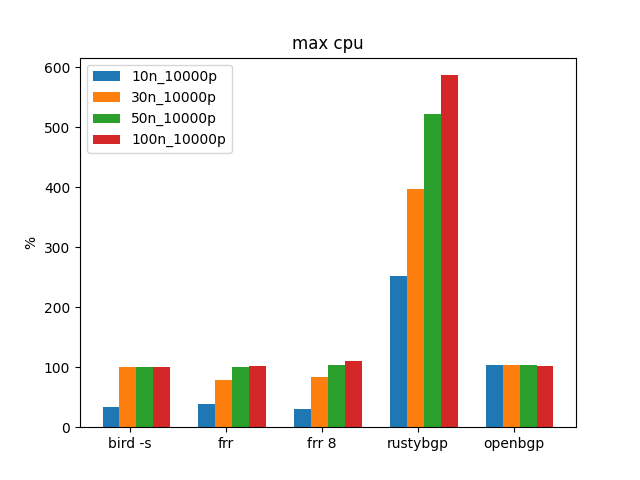
RustyBGP uses a lot more CPU resources, even though it isn’t any faster than FRR or BIRD.
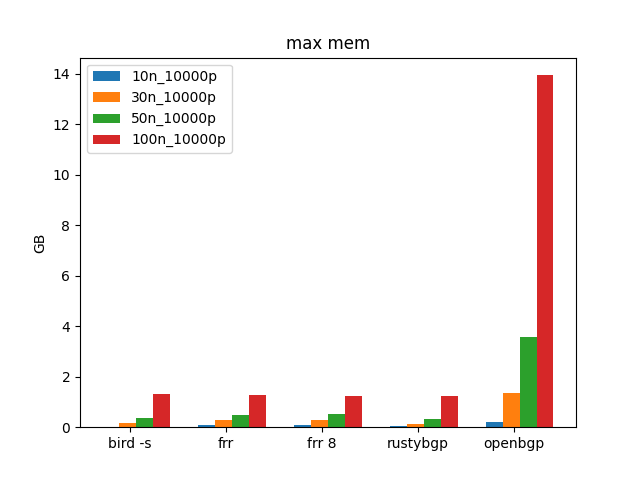
OpenBGPD uses a tremendous amount of memory, especially at 100 neighbors. I’m not sure what’s going on here, but that looks troubling to me.
results table
Many (many) neighbors, 10 prefixes
This iterates through neighbors from 250 to 1750. More than that runs out of memory on my 64 GB machine (because of all the ExaBGP). It uses a very minimal amount of prefixes just to see if we can understand anything regarding max prefixes.
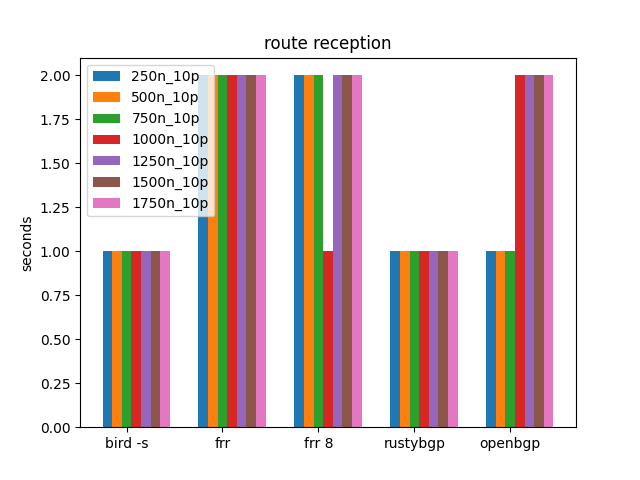
The time to receive prefixes, all 10 per neighbor, doesn’t matter in this test.
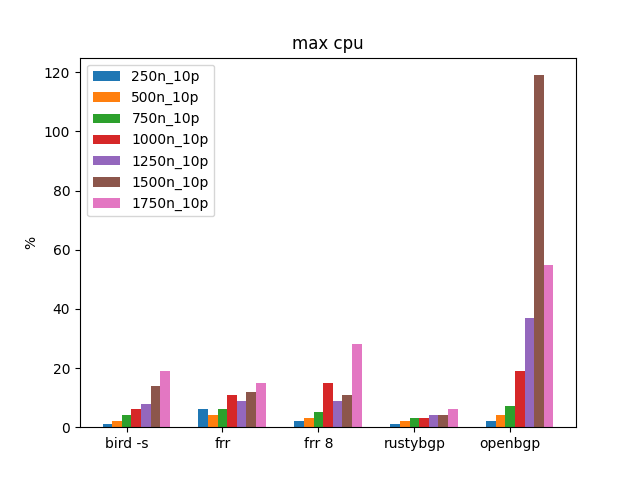
Interestingly, RustyBGP uses the smallest amount of CPU and OpenBGPD uses the most, by a lot. FRRouting 8 uses more CPU at 1750 neighbors than 7.5.1. I don’t know that is important since it’s still not very much
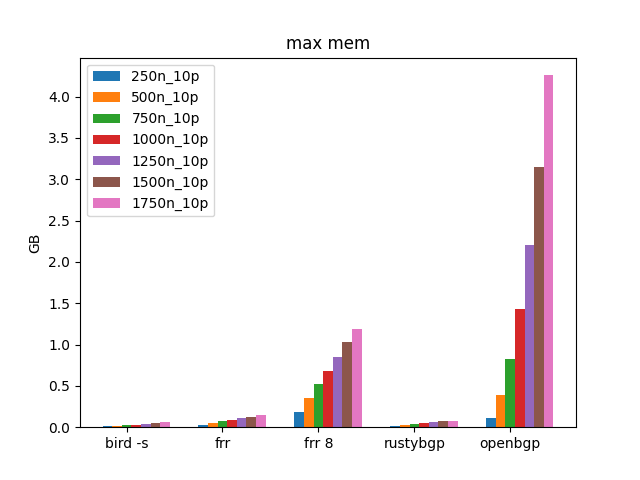
OpenBGPD uses a lot more memory, several orders of magnitude more.
Because it’s so hard to see everything but OpenBGPD, going to remove it so we can look at the others.
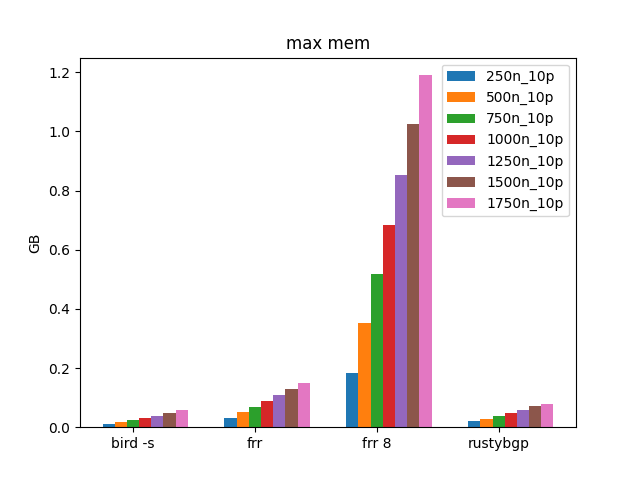
FRRouting 8 uses a lot more memory than FRRouting 7.5.1 or BIRD. Don’t know if this matters because it’s only 10 prefixes, but it’s interesting. There looks like some kind of per neighbor memory tax in FRRouting 8. It is too much? I don’t know. Is it impactful as there are more routes? Let’s see.
results table
Many neighbors, 100 prefixes
This only goes from 250 to 750 neighbors with 100 prefixes. More than that runs out of memory on my 64 GB machine (because of all the ExaBGP processes.)
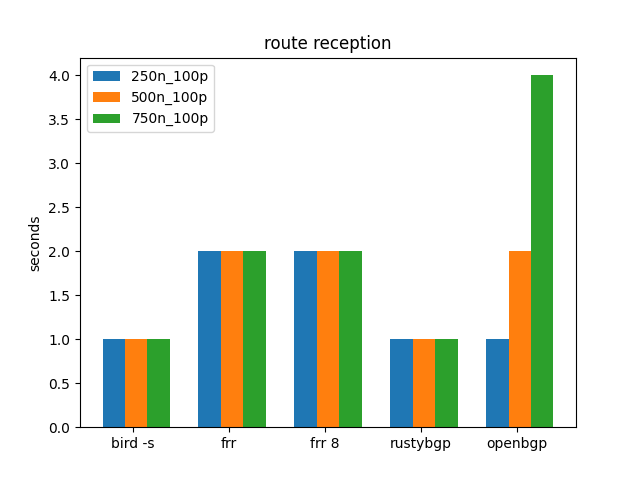
Again, route reception is trivial. Maybe it matters that OpenBGPD at 750 neighbors is 4 seconds, but not sure.
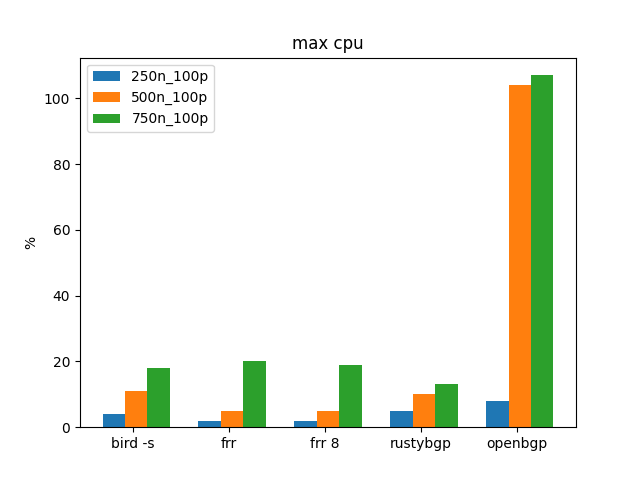
Similar to the 10 prefix tests, OpenBGPD uses many more CPU resources than the others.
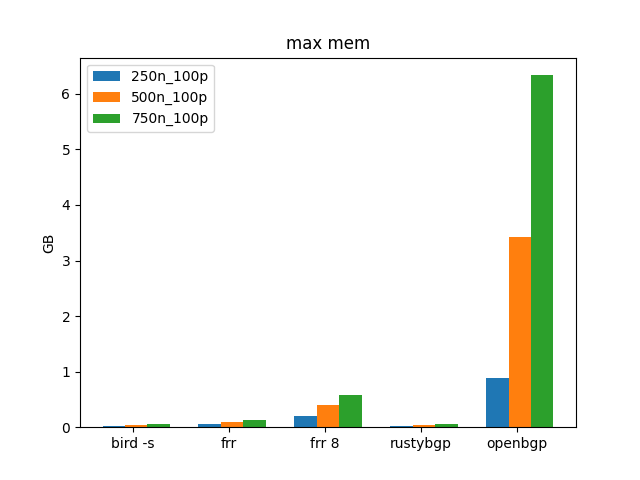
Similar to the 10 prefix tests, OpenBGPD uses many more memory resources than the others. What’s troubling is that at 10 prefixes and 750 neighbors it’s about 1GB but at 100 prefixes, 750 neighbors it’s 6GB.
Let’s again remove OpenBGPD so we can understand the others better.
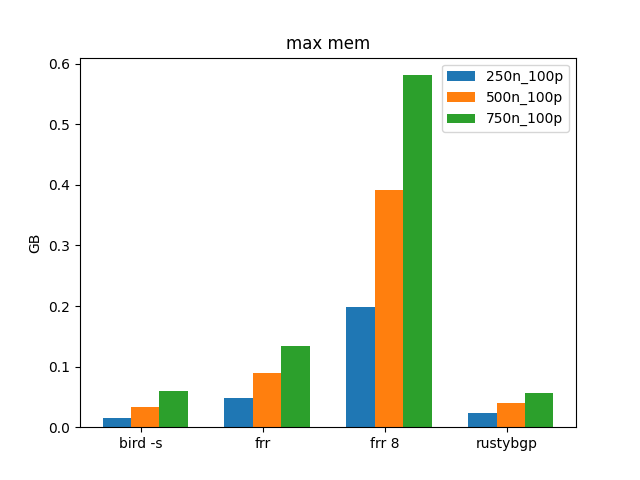
FRRouting 8 is still a lot higher than the others, but it grows to about 0.58 GB from 0.52 at 750 neighbors. That again leads credence to a per neighbor memory tax, but doesn’t seem to be in the way as more prefixes are added.
results table
Prefix iterations
This set of tests iterates from 50 to 250 neighbors and 10 prefixes to 1000.
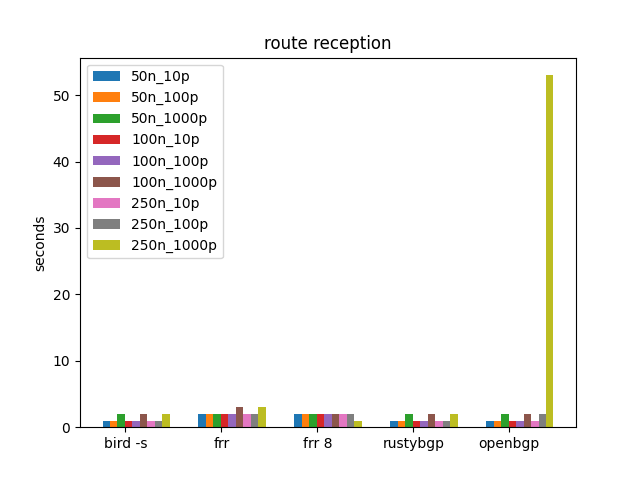
Route Reception is trivial, except OpenBGPD at 250 neighbors, 1000 prefixes. It plain freaks out.
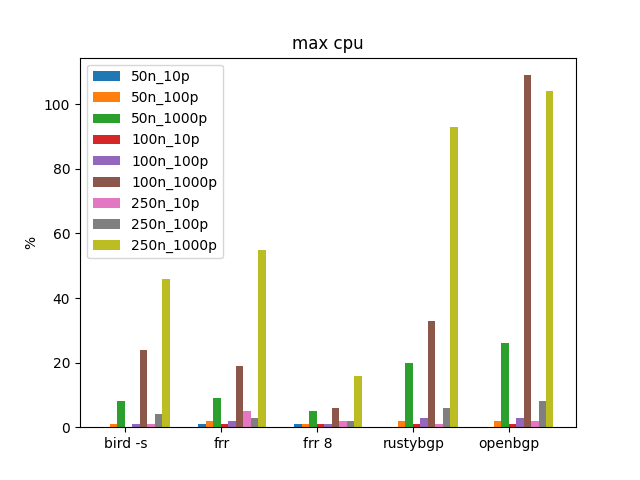
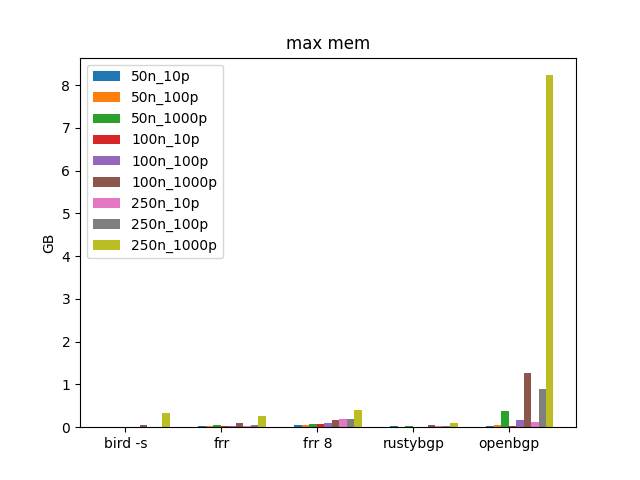
Zoom in without OpenBGPD again.
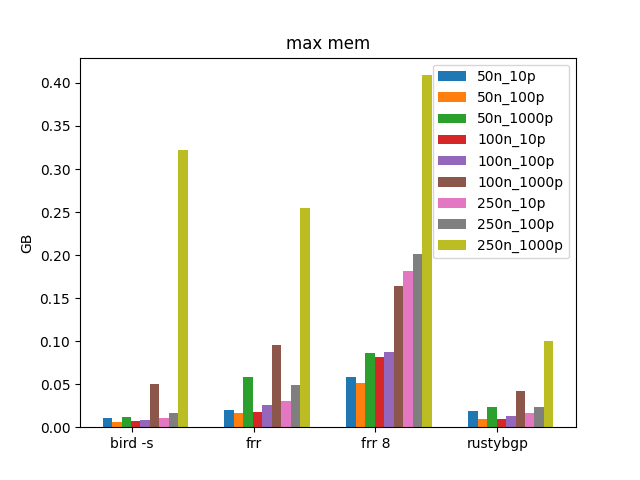
Not sure how to interpret this exactly. It looks like additional routes don’t really matter for memory until 1000 ish. FRRouting 8 still uses more memory but looks like a fixed amount perf neighbor not a percentage, so probably not so concerning. RustyBGP is the lowest memory user still.
results table
1M routes.
Since the internet is getting close to 1M routes, how do these stacks do with 1M routes and multiple neighbors?
CAVEAT As I’ve been thinking about this test I’ve realized it’s not doing a good job of representing actually connecting to internet routes. It’s 1M /32s that are all unique, so in the end, if you have 5 neighbors, you have 5 million routes. It’s what I can do for now, I’ll continue to work on improving this test.
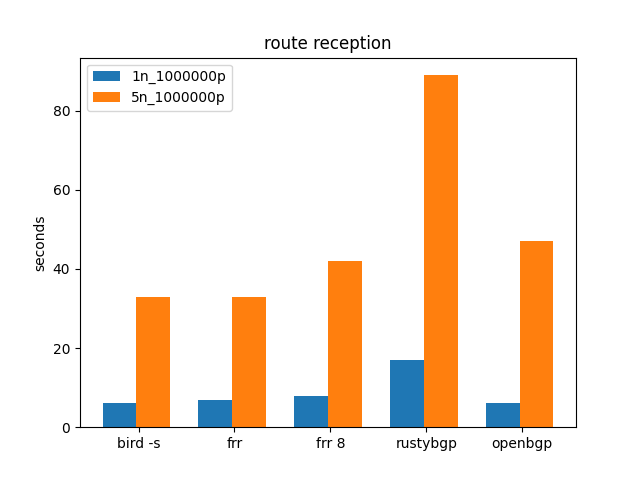
This is the first time that RustyBGP is considerably slower than all the others.
FRR 8 is somewhat slower than 7.5.1 or BIRD. OpenBGPD looks good here.
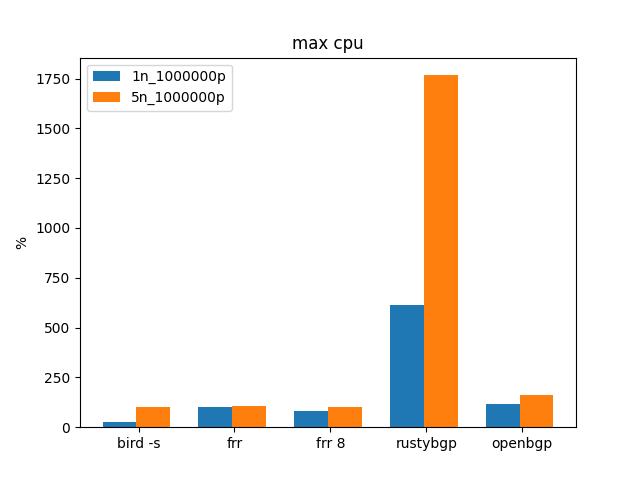
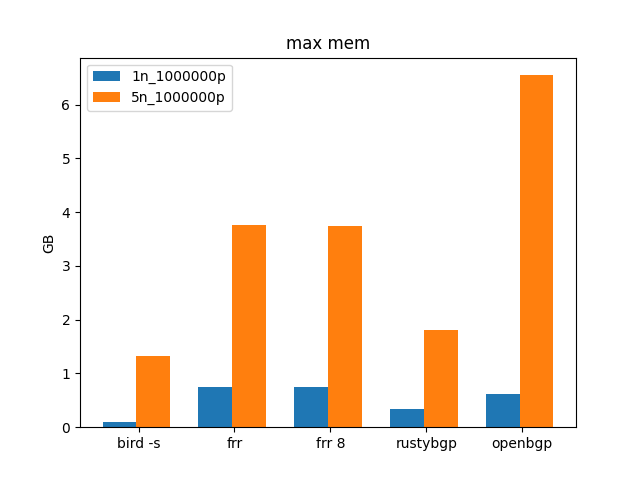
BIRD uses 1/3 the memory of FRRouting. RustyBGP also uses significantly less memory than FRRouting, but it’s slower too. OpenBGPD uses the most memory, as usual.
results table
Results from EC2 m5
I wanted to see what would happen with more resources, specifically twice as much RAM. However, the AMD device is a consumer device with less cores but each higher speed. That might matter to some of these tests because of the single core processes.
I ran the same test suites with some little changes. I won’t go through all the graphs, because there are pretty similiar results. But where there is something interesting I’ll mention that.
10K prefixes
Route Reception has a greater difference between both FRRs and BIRD/RustyBGP. Maybe it’s that 3950 is a consumer device with higher speed cores?
results table
Many (many) neighbors, 10 prefixes
I didn’t find any interesting differences here.
results table
Many neighbors, 100 prefixes
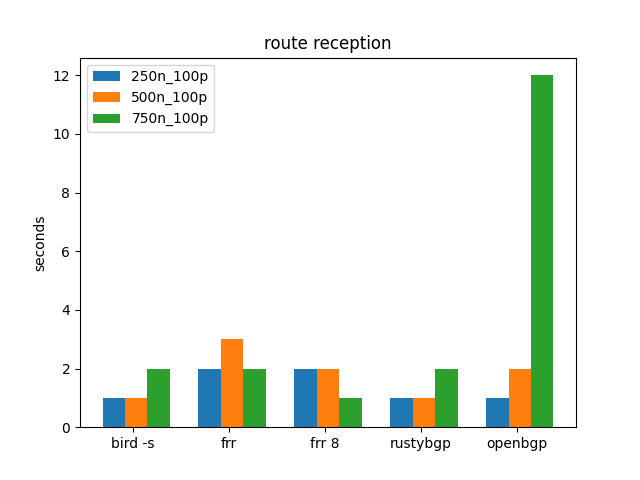
OpenBGPD at 750 neighbors is a lot greater route reception time than on the AMD.
results table
Prefix iterations
Because of more memory, I tested to 500 neighbors.
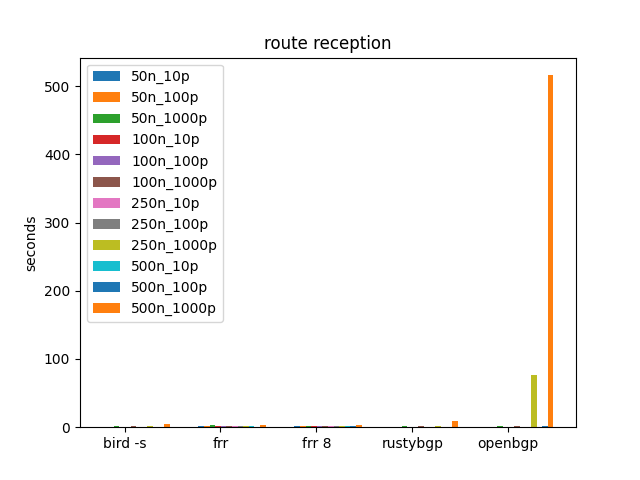
OpenBGPD is an order of magnitude worse at 500 neighbors, 1000 prefixes, then at 250.
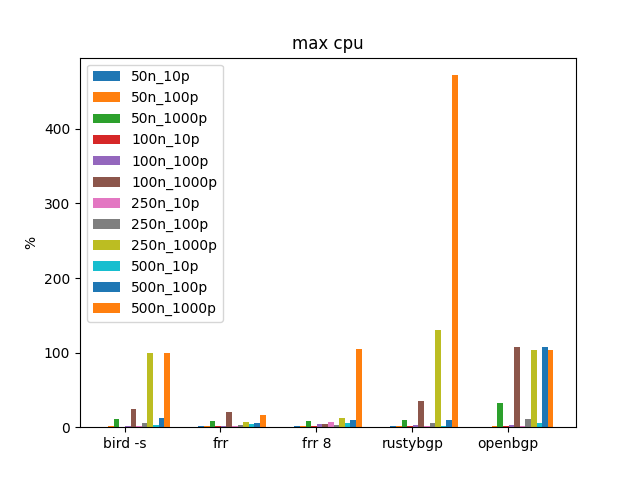
We see Rusytbgp jump up in CPU usage at 500 neighbors. On the AMD is never got past 100%.
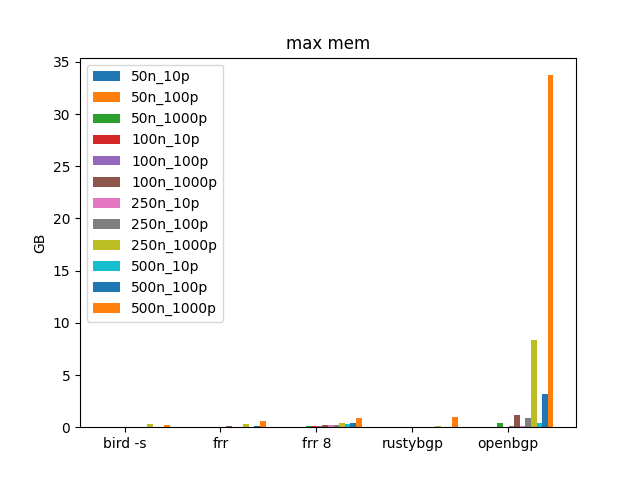
OpenBGPD is using over 30GB of RAM and is slow at 500 neighbors.
results table
1M routes.
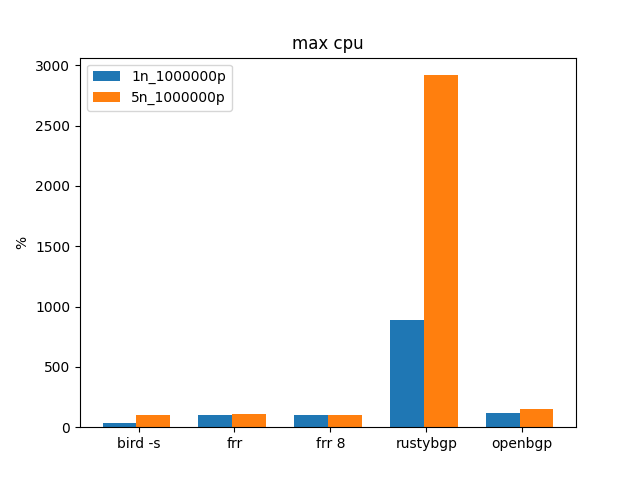
RustyBGP uses twice as much CPU as the AMD, but is still slower than all the others.
results table
Results from EC2 t3
I wanted to try out what would happen on a machine with more limited resources. As with the above, these are the same suite of tests, with some little limitations because of less memory. The biggest issue is that because the target stack and the tester, and the monitor, are all on the same hardware they fight for resources, especially in the many neighbors test. I’m still trying to understand the impact of bgperf on the results.
10K prefixes
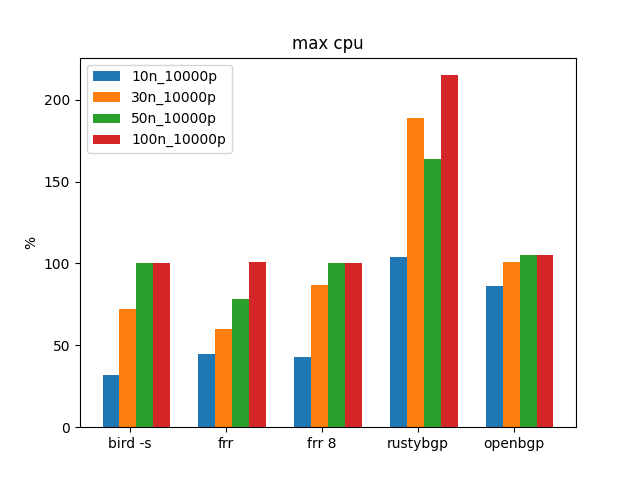
It’s interesting that RustyBGP uses less CPU, because there is less, but it’s not much slower than on the other machines. What is it doing with those other CPU resources when it has them?
Many (many) neighbors, 10 prefixes
Can only test many less parameters because of memory.
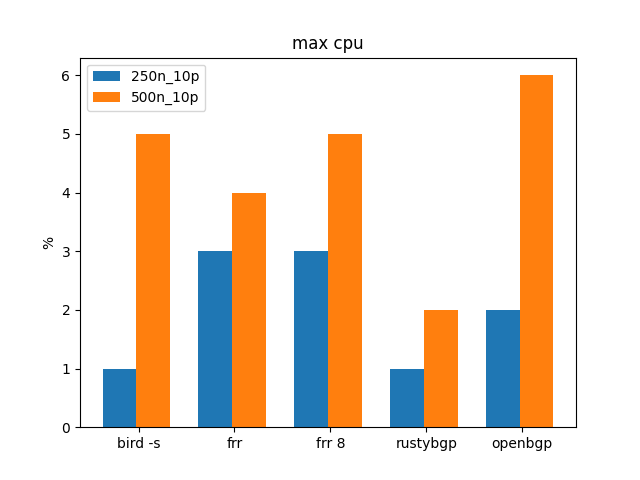
While not really different, it is interesting to zoom in on just 250 and 500 neighbors.
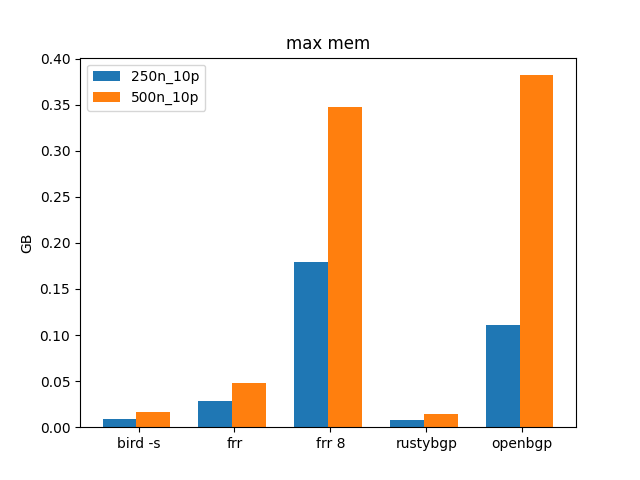
Again, not much different, but zooming in shows the difference in memory between FRRouing 8/OpenBGPD vs the others.
Many neighbors, 100 prefixes
Nothing interestingly different here.
Prefix iterations
Nothing interestingly different here.
1M routes.
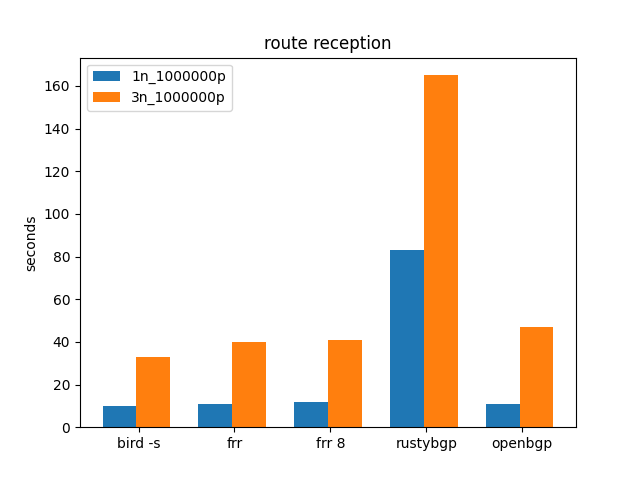
While the others are about the same, RustyBGP doubles it’s time here.
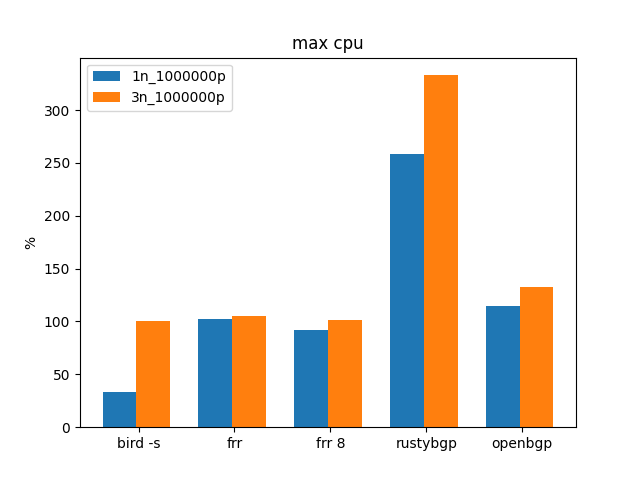
Just a lot less CPU resources for RustyBGP to use.
More extreme tests
After doing those suite of tests across all three different hardware, I realized that in some cases it’s still telling us more about how much resources the test suite uses than the limits of these stacks. These no longer test OpenBGPD (or GoBGP) because it is so much less performant than the other stacks. I can’t use my own AMD machine because these tests run out of memory, so this is all EC2 hardware.
10 Prefixes, Many Many Neighbors
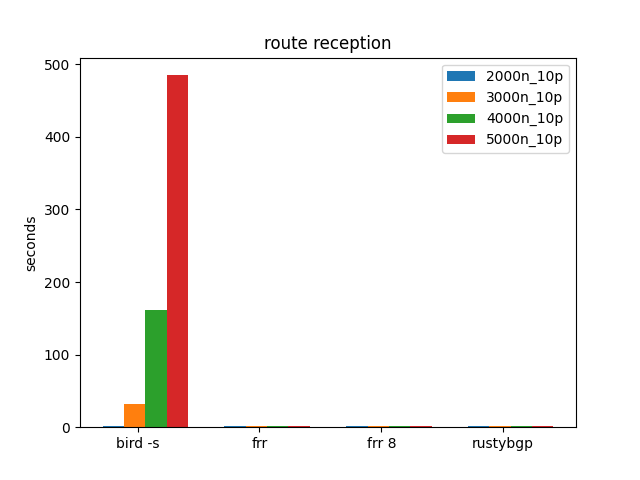
Ooop, right away, something interesting. above 3000 neighbors BIRD gets sad/mad. We seem to have found a boundary in BIRD where it gets much worse
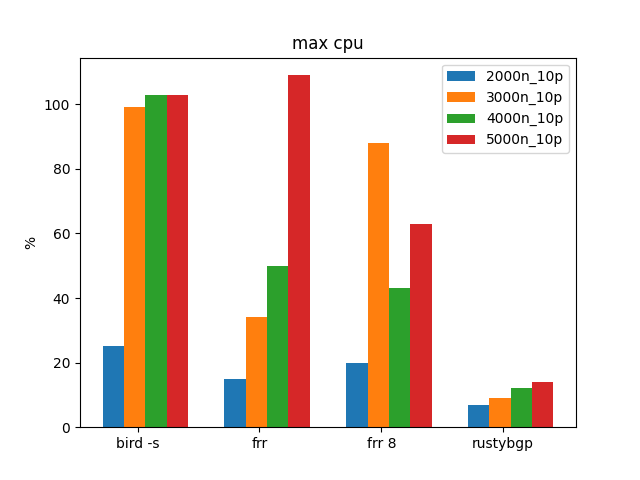
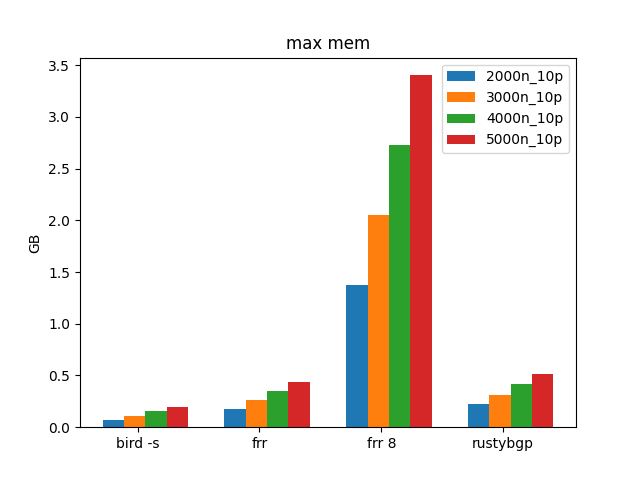
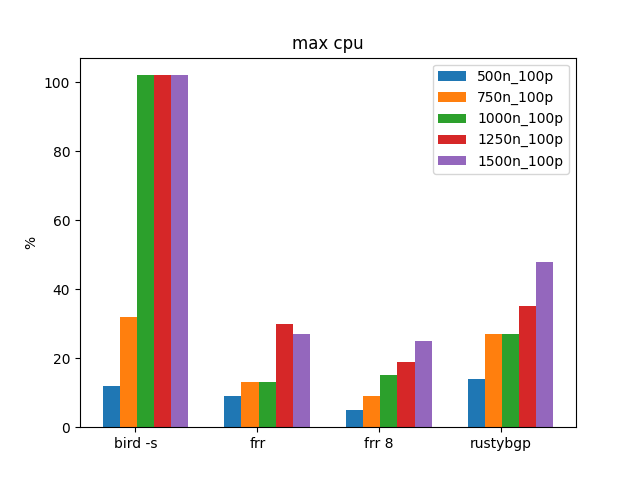
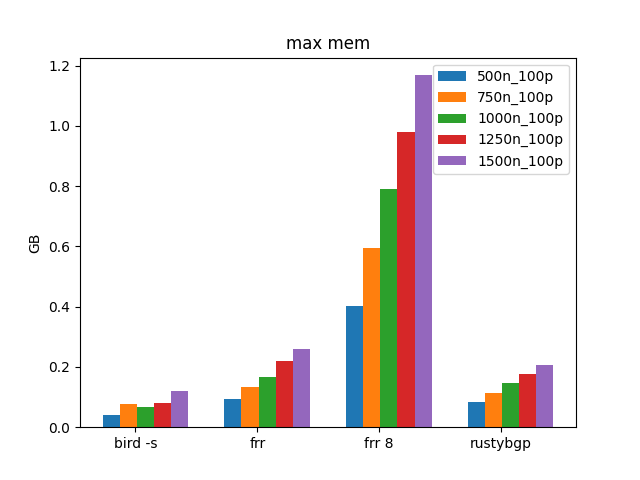
100 Prefixes, Many Neighbors
In the above tests, there was a test for 100 Prefixes up to 750 neighbors. Let’s go bigger and see what we see.
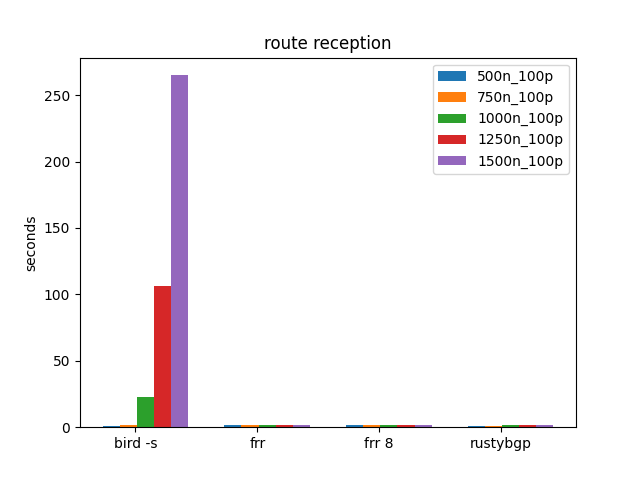
Above 1000 neighbors BIRD gets sad/mad. In the above tests we did over 1000 neighbors with BIRD, but with only 10 prefixes.
1000 Prefixes, Many Neighbors
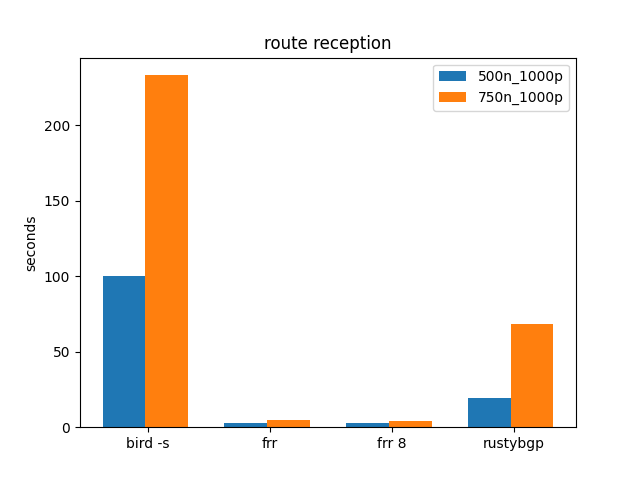
Once again, BIRD is mad. RustyBGP also is > an order of magnitude slower than FRRouting.
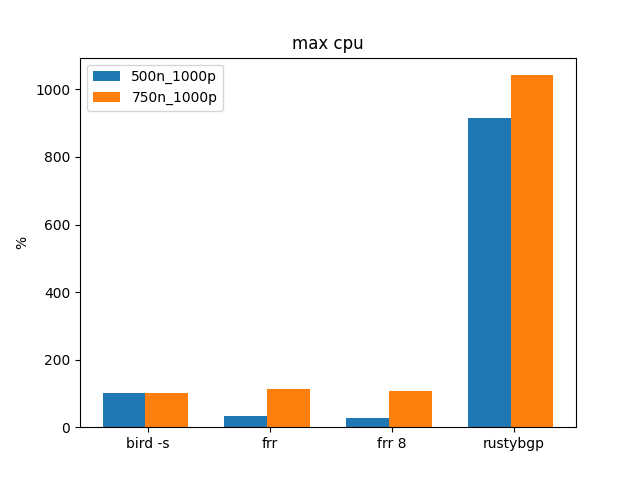
RustyBGP is using lots of CPU here. It looks like FRRouting doesn’t get to 100% CPU until there are 750 neighbors here.
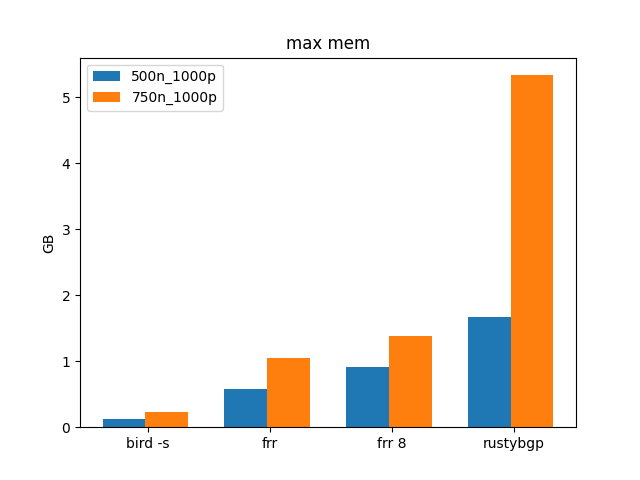
Interestingly, BIRD uses the least amount of memory. RustyBGP uses a lot of memory for RustyBGP. It is usually the lowest or near the lowest memory users in these tests, but not here.
Observations
These tests use quite a bit of hardware in CPU and memory. Most of those resources are going into ExaBGP sending the prefixes rather than in the targets. In some ways this is a test of the test system. I’m still figuring out how to best test the targets without the test system getting in the way.
RustyBGP
I’ve seen twitter claims that RustyBGP is significantly faster that FRRouting, but I can’t reproduce that here. I’m sure I’m missing something. RustyBGP is still missing a lot of necessary BGP daemon features, I’m just not testing them.
BIRD
BIRD with more than 1000 neighbors and more than just a handful of prefixes becomes problematic. And with 1000 prefixes, By 500 neighbors it’s performing badly again. I don’t know what it is exactly that is the bottleneck here.
Conclusion
OpenBGP struggles in places that the other stacks do not, but it’s still faster than GoBGP. For anybody running OpenBGP, are there scenarios that make it more useful than the other stacks? All other things being equal, if performance or memory use matters, it looks like OpenBGP is the loser here.
Not sure the winner, maybe FRRouting 7.5.1? Is that enough to not use FRRouting 8? I doubt it, but I’m not testing functionality, just straight up speed on these simple tests. There are some cases in which RustyBGP is faster or uses less memory.
I’m not really going to declare a winner.
Try out bgperf yourself.
Questions
There are probably patterns in here that I missed. What analysis did I miss looking through this data?
Are the scenarios that I’m using to test useful? Are there different combinations of prefixes and neighbors that I should be testing?
Does anybody else have either BGP testing tools that they can share, or other results that they can share?
followup / todo
Still more to do to be more representative of real loads and not so artificial.